Introduction to MLPs using US Census Income Data¶
I developed this notebook for Week 3 of a course, AI for Good, that I co-teach with Professor Zia Mehrabi. In this notebook, we'll use a simple MLP to predict whether an individual makes over or under $50,000 per year based on some demographic characteristics. This notebook was created largely from this one. The dataset we'll use is on Kaggle here.
Learning outcomes:
- Pull in data on Kaggle
- Inspect and explore the data
- Split the dataset into train/test
- Train classical machine learning models on the data
- Build and train simple ANN with Pytorch for classification
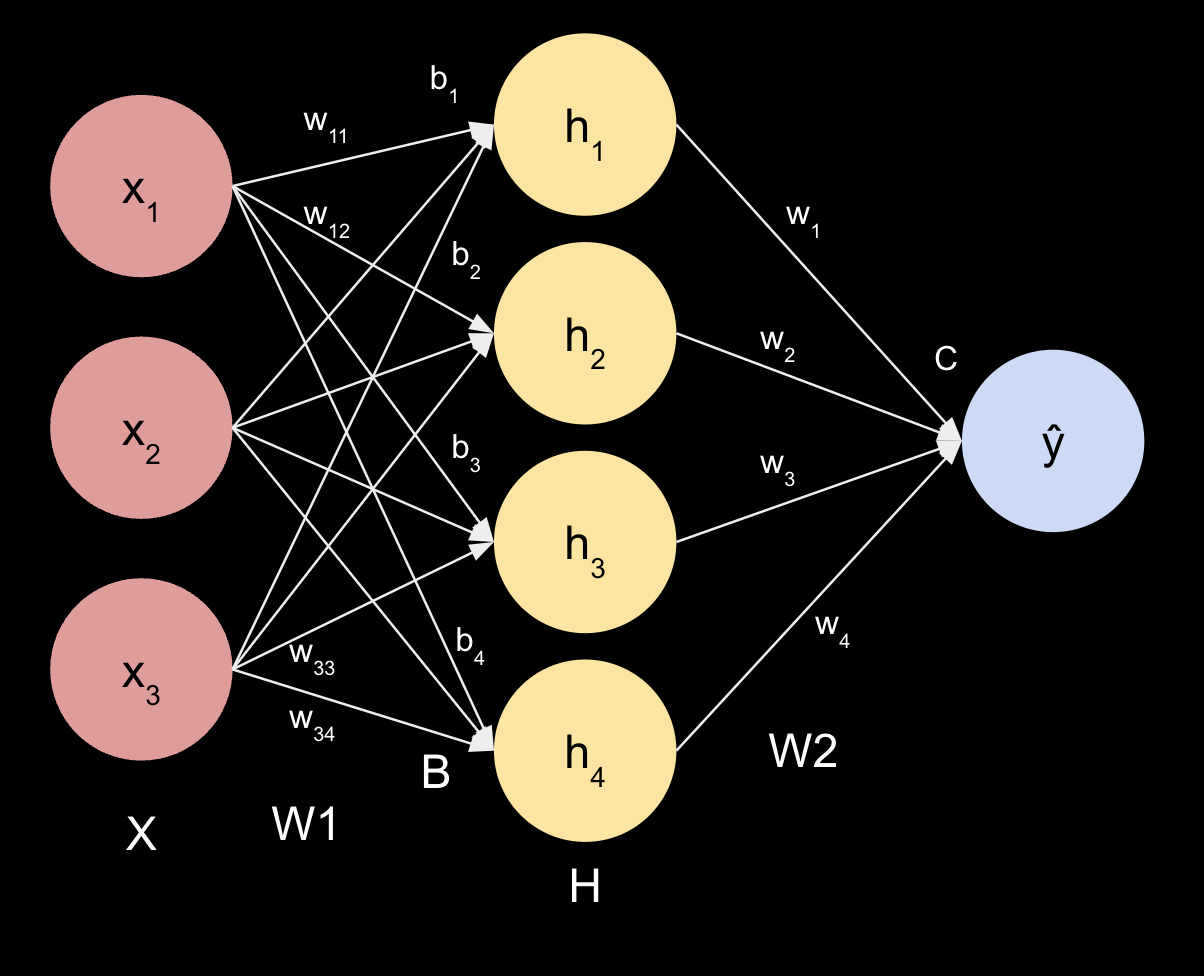
Income Predictor Dataset - US Adult¶
Link: https://www.kaggle.com/datasets/jainaru/adult-income-census-dataset/data
The Adult Census Income dataset, extracted from the 1994 US Census Database by Barry Becker, serves as a valuable resource for understanding the intricate interplay between socio-economic factors and income levels. Comprising anonymized information such as occupation, age, native country, race, capital gain, capital loss, education, work class, and more, this dataset offers a comprehensive view of the American demographic landscape.
Dataset Overview The dataset consists of two CSV files: adult-training.txt and adult-test.txt, each row representing an individual. Key features include occupation, age, native country, race, capital gain, capital loss, education, work class, and more. The target variable, 'income_bracket', categorizes individuals into two groups: ">50K" and "<=50K".
Exploration and Preprocessing Exploring the dataset reveals a mix of categorical and continuous features, as well as missing values. Understanding the distribution and relationships of these features is crucial for feature selection and data preprocessing, including handling missing values and encoding categorical variables.
Modeling and Evaluation To predict income levels, various classifiers can be trained on the training dataset and evaluated using the test dataset. Algorithms such as logistic regression, decision trees, random forests, and neural networks can be employed based on the dataset's complexity and the desired performance metrics.
Environment Setup¶
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
Data Exploration & Cleaning¶
data = pd.read_csv('data/adult.csv') # read in the file
data.head() # look at the first few rows of the dataframe
| age | workclass | fnlwgt | education | education.num | marital.status | occupation | relationship | race | sex | capital.gain | capital.loss | hours.per.week | native.country | income | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 90 | ? | 77053 | HS-grad | 9 | Widowed | ? | Not-in-family | White | Female | 0 | 4356 | 40 | United-States | <=50K |
| 1 | 82 | Private | 132870 | HS-grad | 9 | Widowed | Exec-managerial | Not-in-family | White | Female | 0 | 4356 | 18 | United-States | <=50K |
| 2 | 66 | ? | 186061 | Some-college | 10 | Widowed | ? | Unmarried | Black | Female | 0 | 4356 | 40 | United-States | <=50K |
| 3 | 54 | Private | 140359 | 7th-8th | 4 | Divorced | Machine-op-inspct | Unmarried | White | Female | 0 | 3900 | 40 | United-States | <=50K |
| 4 | 41 | Private | 264663 | Some-college | 10 | Separated | Prof-specialty | Own-child | White | Female | 0 | 3900 | 40 | United-States | <=50K |
data.info() # look at the various columns and their data types
<class 'pandas.core.frame.DataFrame'> RangeIndex: 32561 entries, 0 to 32560 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 32561 non-null int64 1 workclass 32561 non-null object 2 fnlwgt 32561 non-null int64 3 education 32561 non-null object 4 education.num 32561 non-null int64 5 marital.status 32561 non-null object 6 occupation 32561 non-null object 7 relationship 32561 non-null object 8 race 32561 non-null object 9 sex 32561 non-null object 10 capital.gain 32561 non-null int64 11 capital.loss 32561 non-null int64 12 hours.per.week 32561 non-null int64 13 native.country 32561 non-null object 14 income 32561 non-null object dtypes: int64(6), object(9) memory usage: 3.7+ MB
# look for null values and duplicate rows
print("Null values by column:\n", data.isnull().sum())
print("Number of duplicate rows: ", data.duplicated().sum())
Null values by column: age 0 workclass 0 fnlwgt 0 education 0 education.num 0 marital.status 0 occupation 0 relationship 0 race 0 sex 0 capital.gain 0 capital.loss 0 hours.per.week 0 native.country 0 income 0 dtype: int64 Number of duplicate rows: 24
# clean the data and reinspect
data.drop_duplicates(inplace=True) # drop the duplicate rows
data.replace('?', np.nan, inplace=True) # replace any values with a ? with "NaN" or "Not a Number"
data.dropna(inplace=True) # drop any rows that have NA values
data.info() # inspect data again
<class 'pandas.core.frame.DataFrame'> Index: 30139 entries, 1 to 32560 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 30139 non-null int64 1 workclass 30139 non-null object 2 fnlwgt 30139 non-null int64 3 education 30139 non-null object 4 education.num 30139 non-null int64 5 marital.status 30139 non-null object 6 occupation 30139 non-null object 7 relationship 30139 non-null object 8 race 30139 non-null object 9 sex 30139 non-null object 10 capital.gain 30139 non-null int64 11 capital.loss 30139 non-null int64 12 hours.per.week 30139 non-null int64 13 native.country 30139 non-null object 14 income 30139 non-null object dtypes: int64(6), object(9) memory usage: 3.7+ MB
Now that we've dropped all duplicate rows and all rows with ? or null values, next we need to convert our variables with categorical answers to numeric values, extract our label, and scale our numeric values. For this, we'll use the classical machine learning library sci-kit-learn.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
# one hot encode the categorical features
categorical_features = ['workclass', 'education', 'marital.status', 'occupation',
'relationship', 'race', 'sex', 'native.country', 'income']
for feature in categorical_features:
le = LabelEncoder()
data[feature] = le.fit_transform(data[feature])
# extract the label column
X = data.drop('income', axis=1)
y = data['income']
# scale the numeric features to each have a mean of 0, std dev of 1
continuous_features = ['age', 'fnlwgt', 'education.num', 'capital.gain', 'capital.loss', 'hours.per.week']
scaler = StandardScaler()
X[continuous_features] = scaler.fit_transform(X[continuous_features])
# split the data into train/test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
PyTorch & Tensors¶
Tensors are a specialized data structure that are very similar to arrays and matrices. In PyTorch, we use tensors to encode the inputs and outputs of a model, as well as the model’s parameters.
Tensors are similar to NumPy’s ndarrays, except that tensors can run on GPUs or other hardware accelerators. In fact, tensors and NumPy arrays can often share the same underlying memory, eliminating the need to copy data (see Bridge with NumPy). Tensors are also optimized for automatic differentiation (we’ll see more about that later in the Autograd section). If you’re familiar with ndarrays, you’ll be right at home with the Tensor API.
Learn more here: https://pytorch.org/tutorials/beginner/basics/tensorqs_tutorial.html
To start let's import the libraries we need from PyTorch.
import torch
from torch.utils.data import DataLoader, TensorDataset
import torch.nn as nn
import torch.optim as optim
# convert test and training data to a tensor
X_train_tensor = torch.tensor(X_train.values, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.long)
X_test_tensor = torch.tensor(X_test.values, dtype=torch.float32)
y_test_tensor = torch.tensor(y_test.values, dtype=torch.long)
Datasets & Dataloaders¶
Code for processing data samples can get messy and hard to maintain; we ideally want our dataset code to be decoupled from our model training code for better readability and modularity. PyTorch provides two data primitives: torch.utils.data.DataLoader and torch.utils.data.Dataset that allow you to use pre-loaded datasets as well as your own data. Dataset stores the samples and their corresponding labels, and DataLoader wraps an iterable around the Dataset to enable easy access to the samples.
Learn more here: https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
# create a TensorDataset within Pytorch
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
# wrap the Dataset in a DataLoader to be iterable
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
Get Device for Training¶
We want to be able to train our model on a hardware accelerator like the GPU or MPS, if available. Let’s check to see if torch.cuda or torch.backends.mps are available, otherwise we use the CPU.
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
Using mps device
Build a Machine Learning Model¶
Here's the fun part, building the machine learning model! Pytorch makes this relatively straightforward. Let's start with a very simple model.
class NeuralNetwork(nn.Module):
def __init__(self, input_dim):
super().__init__()
self.linear_relu_stack = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 2),
nn.ReLU(),
)
def forward(self, x):
x = self.linear_relu_stack(x)
return x
# figure out the width of the input tensor
print('The shape of the X_train_tensor is:', X_train_tensor.shape)
# let's use the second value, the # of columns
input_dim = X_train_tensor.shape[1]
# instantiate the model
model = NeuralNetwork(input_dim)
The shape of the X_train_tensor is: torch.Size([24111, 14])
Train a Neural Network¶
First step is to define our training parameters. The three key ones are:
- Loss Function (https://pytorch.org/docs/stable/nn.html#loss-functions)
- Learning Rate (https://www.geeksforgeeks.org/impact-of-learning-rate-on-a-model/)
- Optimizer (https://pytorch.org/docs/stable/optim.html)
# define a loss function
criterion = nn.CrossEntropyLoss() # a go to for classication problems
learning_rate = 0.001 # a standard starting point, use factors of 10
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # Adam Optimizer: https://arxiv.org/abs/1412.6980
Now it's time for the training loop. The following code will define how many times we want to loop over the training data, and then executes that loop, running the data through the model with each batch, calculating the loss, and updating the model parameters accordingly.
# Set the number of times to iterate over the entire training dataset
num_epochs = 30
# Start the training loop, iterating through the dataset `num_epochs` times
for epoch in range(num_epochs): # Loop over each epoch
model.train() # Put the model into training mode (enables features like dropout)
running_loss = 0.0 # Initialize a variable to keep track of cumulative loss for the epoch
# Loop through each batch of data in the training dataset
for inputs, labels in train_loader: # `inputs` are the features, `labels` are the targets
optimizer.zero_grad() # Clear the gradients from the previous step
outputs = model(inputs) # Perform a forward pass through the model to get predictions
loss = criterion(outputs, labels) # Compute the loss between predictions and actual labels
loss.backward() # Perform backpropagation to calculate gradients of loss with respect to parameters
optimizer.step() # Update model parameters based on the gradients
running_loss += loss.item() # Accumulate the loss for this batch
# Calculate the average loss for this epoch
avg_loss = running_loss / len(train_loader) # Divide total loss by the number of batches
# Print progress, showing the current epoch and average loss for the epoch
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')
Epoch [1/30], Loss: 0.4452 Epoch [2/30], Loss: 0.3727 Epoch [3/30], Loss: 0.3559 Epoch [4/30], Loss: 0.3429 Epoch [5/30], Loss: 0.3401 Epoch [6/30], Loss: 0.3345 Epoch [7/30], Loss: 0.3363 Epoch [8/30], Loss: 0.3340 Epoch [9/30], Loss: 0.3323 Epoch [10/30], Loss: 0.3305 Epoch [11/30], Loss: 0.3302 Epoch [12/30], Loss: 0.3278 Epoch [13/30], Loss: 0.3257 Epoch [14/30], Loss: 0.3263 Epoch [15/30], Loss: 0.3248 Epoch [16/30], Loss: 0.3233 Epoch [17/30], Loss: 0.3224 Epoch [18/30], Loss: 0.3201 Epoch [19/30], Loss: 0.3210 Epoch [20/30], Loss: 0.3180 Epoch [21/30], Loss: 0.3163 Epoch [22/30], Loss: 0.3166 Epoch [23/30], Loss: 0.3149 Epoch [24/30], Loss: 0.3134 Epoch [25/30], Loss: 0.3131 Epoch [26/30], Loss: 0.3109 Epoch [27/30], Loss: 0.3128 Epoch [28/30], Loss: 0.3107 Epoch [29/30], Loss: 0.3086 Epoch [30/30], Loss: 0.3082
Model Evaluation¶
The code below runs the test data through our trained model, and reports on the performance. Remember, the model did not see this data in training.
model.eval() # Put the model in evaluation mode (disables features like dropout and gradient tracking)
correct = 0 # Initialize a counter for correctly classified samples
total = 0 # Initialize a counter for the total number of samples
with torch.no_grad(): # Disable gradient calculation for efficiency and to save memory
for inputs, labels in test_loader: # Loop through each batch in the test dataset
outputs = model(inputs) # Perform a forward pass through the model to get predictions
_, predicted = torch.max(outputs.data, 1) # Get the class with the highest probability for each sample
total += labels.size(0) # Update the total count with the number of samples in this batch
correct += (predicted == labels).sum().item() # Increment the correct count for accurate predictions
accuracy = 100 * correct / total # Calculate accuracy as a percentage
print(f'Accuracy on test data: {accuracy:.2f}%') # Display the accuracy of the model on the test data
Accuracy on test data: 85.00%
Saving & Loading our Model¶
A common way to save a model is to serialize the internal state dictionary (containing the model parameters).
torch.save(model.state_dict(), "models/income.pth")
print("Saved PyTorch Model State to models/income.pth")
Saved PyTorch Model State to model.pth
# The process for loading a model includes re-creating the model structure and loading the state dictionary into it
model = NeuralNetwork(input_dim)
model.load_state_dict(torch.load("models/income.pth", weights_only=True))
model = model.to(device) # move from cpu to gpu if available
# This model can now be used to make predictions.
classes = ["Over $50k", "Under $50k"] # is this correct, or should it be switched?
row_index_to_test = 2
# evaluate the model on this one item from the dataset
model.eval()
x, y = test_dataset[row_index_to_test][0], test_dataset[row_index_to_test][1]
with torch.no_grad():
x = x.to(device)
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')
Predicted: "Over $50k", Actual: "Over $50k"
Assignment¶
Write your answers to the following questions in a markdown cell at the end of your notebook.
- Play with the MLP model. Consider adding more layers, changing the size of layers, adding things like drop out, etc. Full list of types is here: torch.nn. What model architecture worked best for you?
- Play with the optimization parameters. Try other learning rates, more or less epochs, different loss functions, optimizers, etc. See which one gets a good result fastest. What model parameters worked best for you?
- Reflect on the question, what are some ethical considerations for building a model that classifies people as high or low earners based on their demographics?
Bonus Challenge #1¶
Compare the performance of your neural network to some classical machine learning methods. Does this dataset / problem merit "deep" learning? Why or why not?
Bonus Challenge #2¶
Feature importance: query your best neural network to see which features were the best predictors of income. Which ones were the best predictors?
Bonus Challenge #3¶
Modify your trained network to predict salary as a regression problem.
Export Notebook to HTML¶
# supress warnings
import warnings
warnings.filterwarnings("ignore")
# export to HTML for webpage
import os
os.system('jupyter nbconvert --to html income-mlp.ipynb --HTMLExporter.theme=dark')
[NbConvertApp] Converting notebook income-mlp.ipynb to html [NbConvertApp] Writing 334100 bytes to income-mlp.html
0